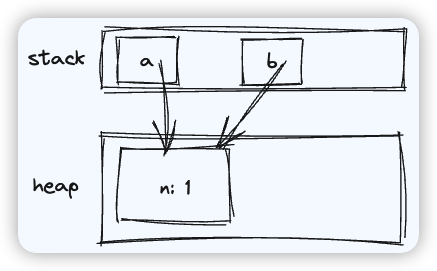
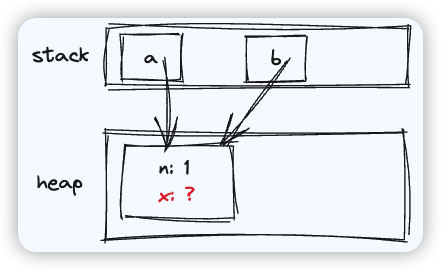
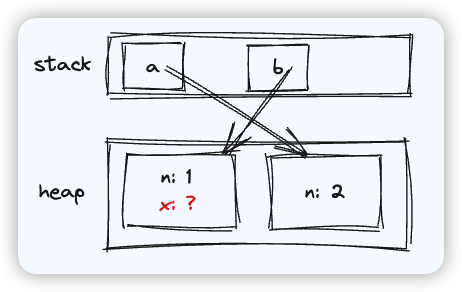
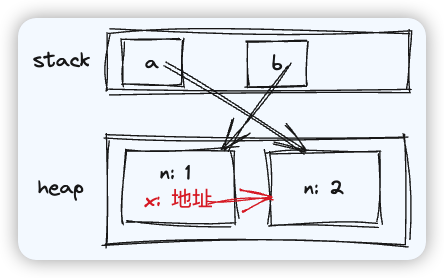
const cache = new Map()
const deepClone = (v) => {
if(v instanceof Object) {
if(cache.get(v)){ return cache.get(v)}
let result = undefined
if(v instanceof Array) {
result = new Array()
} else if(v instanceof Function){
if(v.prototype) {
result = function(){ return v.apply(this, arguments)}
} else {
result = (...args) => { return v.call(undefined, ...args)}
}
} else if(v instanceof Date) {
result = new Date(v - 0)
} else if(v instanceof RegExp) {
result = new RegExp(v.source, v.flags)
} else {
result = new Object()
}
cache.set(v, result)
for(let key in v){
if(v.hasOwnProperty(key)){
result[key] = deepClone(v[key])
}
}
return result
} else {
return v
}
}
const a = {
number:1, bool:false, str: 'hi', empty1: undefined, empty2: null,
array: [
{name: 'frank', age: 18},
{name: 'jacky', age: 19}
],
date: new Date(2000,0,1,20,30,0),
regex: /\.(j|t)sx/i,
obj: { name:'frank', age: 18},
f1: (a, b) => a + b,
f2: function(a, b) { return a + b }
}
a.self = a
const b = deepClone(a)
b.self === b
b.self = 'hi'
a.self !== 'hi'